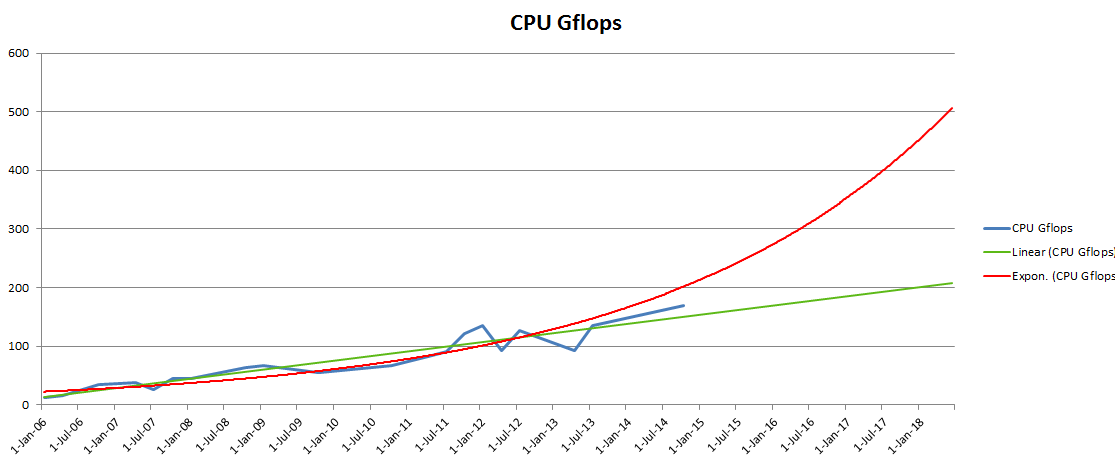
I was happily working away on my 700+ row table in TablePress, saving occasionally. Server issues came up and I was prevented from saving for a few hours. Eventually the server was back up again and I wanted to save, but I ran into the dreaded Ajax save failure message.

Even using shift+save did not work, taking me to the silly and useless Are you sure? WordPress page.
Refreshing the page would have meant losing many hours of work. I tried various ideas but all failed. The most desperate idea was to use jQuery to get the values of all the table cells, put them into an array, copy the string of the array, refresh the page, use jQuery to feed the array back into the cells. I tried to do it in Firefox, using the built-in inspector and Firebug, only to be reminded of how much I dislike Firefox’s slow and clunky inspector tools (I was using Firefox since it performs better than Chrome on super-sized web apps like a massive TablePress table).
So I needed a way to move my work to Chrome, but how? I saved the TablePress page as an HTML document on my computer, then opened it in Chrome. Saving the editor as an HTML document causes the values of the input fields to be saved, thus when I opened it in Chrome all the values of the cells where there.
Next, I used a jQuery bookmark to load jQuery on the page in Chrome, then I ran the following two lines in the console:
my_array = [];
$('textarea').each(function(){ my_array.push($(this).val()); });
The above code loads the values of the textboxes into an array. The Chrome console doesn’t have a way of letting you copy an object or array’s source code so that you can paste it somewhere else, therefore we have to improvise. We know that the console will print out the value of any object, and if it is a string, it will plainly print the string.
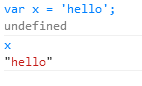
In the above example, we place the word “hello” in the variable x, then on the next line simply write the name of the variable and press enter, causing chrome to give us the string “hello”. As seen below, if type the name of an array variable, Chrome enables us to browse the values inside the array. This is usually helpful, but not this time, since we need the array in format that can be copied.
What we need is to stringify the array somehow. In this case, the JavaScript JSON API comes to the rescue. We place the array my_array inside the my_string variable using the line below:
var my_string = JSON.stringify(my_array);
Afterwards, we type my_string into the console, causing Chrome to show the plaintext version of the array:

We then copy the entire text (making sure to skip the beginning and end quotes added by the stringify function, since we won’t be needing them), then open the TablePress backend on a new tab, loading the table we were working on. The table will lack the cells we had added but could not save. Now we populate this working backend with the data we copied. We open the console, re-enable jQuery using the bookmark, and use the following line to load the text into an array. We do not have a need to use the JSON API’s parse function, since the plaintext is already a valid array initialization.
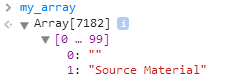
Below we see the array my_array, ready to be populated with the string we copied:

Next, we use the line below to add the values of the array into the table:
$('textarea').each(function(){ $(this).val(my_array.shift()); });
All done! In the first .each function above, we used my_array.push() to add values to the end of the array. To keep the values in order, we now use my_array_.shift(), getting items from the beginning of the array and feeding them to the textareas from first to last.
In this way I managed to get my work back. Another solution I could have tried would have been to see if WordPress could be forced to accept the data that it was rejecting (it was rejecting it due to an expired session or something like that). But such a solution may have required a lot more work and possibly modifications to the WordPress core, which is always risky and not fun.