- Move the yellow playback marker far to the right, until it goes into the blank area and the preview window becomes black. If you are doing batch work, move the marker farther than any of your clips are going to be. For example, if you are exporting 1 minute videos, move the marker to the 2 minute mark.
- On the bar below the playback marker’s bar, find the right end of the selection bar and move it to the far left, so that there are 0 seconds selected. The left end of the selection marker should also be to the far left, obviously.
- That’s all. Now when exporting, Premiere will automatically select the entire sequence for export.
Blog
AWS Storage Historical Pricing and Future Projections
Some blogs are calling the recent price wars between cloud providers “a race to zero”. But this is the wrong way to think about it. As technology progresses, we simply need to start thinking in terms of larger units.
Here is a table of historical Amazon S3 prices:
| Date | $/GB/Month | $/TB/Month |
| 14-Mar-06 | 0.15 | 150 |
| 1-Nov-08 | 0.15 | 150 |
| 1-Nov-10 | 0.14 | 140 |
| 1-Feb-12 | 0.125 | 125 |
| 1-Dec-12 | 0.095 | 95 |
| 1-Feb-14 | 0.085 | 85 |
| 1-Apr-14 | 0.03 | 30 |
In terms of gigabytes the prices seem to be approaching zero. But in terms of terabytes, the prices are just barely starting to become reasonable. The linear projection below suggests that we will be using terabytes as our unit of choice when speaking of cloud storage until 2020 and later, when prices will start going below $1 per terabyte per month.

Some time after 2020, perhaps around 2025, we will start speaking in terms of petabytes per month.
Fire Phone folder where screenshots are stored
Using my Windows 7 computer to browse the Fire Phone’s files, I found the screenshots in the following folder:
Computer\Fire\Internal storage\Pictures\Screenshots
To take screenshots, you need to hold down the volume down and power buttons together. You will hear a sound and see an animation informing you that the screenshot was successfully taken.
Horoscopes and Islam
A Muslim should believe or read horoscopes or not? Because I saw a post that says the person who believes in horoscopes is a disbeliever.
Horoscopes go under the category of superstition, since there is no basis in science or religion for them. Therefore a well educated and intelligent Muslim should take them for what they are: Fancy-sounding nonsense that impress the gullible.
However, we should not be judgmental toward those who believe in horoscopes. Even though this is an obvious flaw in their faith, we ourselves may have greater flaws that are not so apparent. Those who take pleasure in attacking the obvious flaws of others almost certainly have similar or greater flaws themselves.
We shouldn’t be quick to say who is a believer and who is a disbeliever. We can say a person who is not thankful toward God is a disbeliever; but we all show unthankfulness toward God every now and then; therefore are we to say that we are all disbelievers? We should not pass final judgment on people, that is God’s job, not ours. A person who has a part of disbelief in him or her may also have many parts of belief and goodness that outweigh the disbelief.
List of 20,000 right-angled triangles with whole-number sides
Some mathematical investigations can benefit from having a handy list of right-angled triangles with whole number sides. We know of the common [a = 3,b = 4, c = 5] triangle often used to illustrate the Pythagorean theorem (5^2 = sqrt(3^2 + 4^2)), but sometimes we need more of these. For this reason I made the following lists, placed inside handy text files. They start from the smallest possible triangle (the [3,4,5] one) and iterate up.
Mashing two regular expressions together in JavaScript on the fly
var pattern1 = /Aug/; var pattern2 = /ust/; var fullpattern = (new RegExp( (pattern1+'').replace(/^\/(.*)\/$/,'$1') + (pattern2+'').replace(/^\/(.*)\/$/,'$1') ));
Explanation:
pattern1+''turns (“casts”) the regular expression object into a string..replace(/^\/(.*)\/$/,'$1')removes the beginning and ending slashes from the patternnew RegExp()turns the resultant string into a regular expression object. There is no need to add back a regular expression delimiter (i.e. slashes usually) since theRegExp()function (“constructor”) adds the delimiter if it is lacking.- If you want the resultant expression to have a flag, for example
i, you add it so:new RegExp(string,'i'); - This code is quite unreadable and you might be doing yourself and others a kindness if you use a less clever method. To make it more readable, the technique can be wrapped in a function:
var rmash = function(reg1,reg2) {
var fullpattern = (new RegExp( (reg1+'').replace(/^\/(.*)\/$/,'$1') + (reg2+'').replace(/^\/(.*)\/$/,'$1') ));
return fullpattern;
};
var my_new_pattern = rmash(pattern1,pattern2);
Generalizing the mash function to handle an arbitrary number of regular expressions and flags is left as an exercise.
How to do long-running computations in JavaScript while avoiding the “maximum call stack size exceeded” error
The following program calculates the value of the series of the Basel Problem. The result is a number that starts with 1.644934. Like π, this sequence can go on forever, which means the program never exits. Without proper design, such a program runs into the maximum call stack size exceeded error, which is designed to prevent a program from using too much memory.
var cr = 1;
var total = 0;
var x = function() {
total = total + (1/(cr*cr));
if(! (cr % 20000)) {
$('#t1').val(total);
$('#t2').val(cr);
setTimeout(x,0);
}
else {
x();
}
cr++;
};
x(); //initial call to x().
The solution is to add a setTimeout call somewhere in the program before things get too close to exceeding the call stack. In the above program, cr is a counter variable that starts with 1 and increases by 1 for every iteration of the x function. Using the conditional if(! (cr % 20000)) allows the program to catch its breath every 20,000 iterations and empties the call stack. It checks whether cr is divisible by 20,000 without a remainder. If it is not, we do nothing and let the program run its course. But if is divisible without a remainer, it means we have reached the end of a 20,000 iteration run. When this happens, we output the value of the total and the cr variables to two textboxes, t1 and t2.
Next, instead of calling x() the normal way, we call it via setTimeout(x,0);. As you know, setTimeout is genearlly used to run a function after a certain amount of time has passed, which is why usually the second argument is non-zero. But in this case, we do not need any wait time. The fact that we are calling x() via setTimeout is what matters, as this breaks the flow of the program, allowing proper screen output of the variables and the infinite continuation of the program.
The program is extremely fast, doing 1 million iterations about every 2.4 seconds on my computer. The result (the value of total) is not perfectly accurate due to the limitations of JavaScript numbers. More accuracy can be had using an extended numbers library.
You may wonder why we cannot put all calls to x() inside a setTimeout(). The reason is that doing so prevents the JavaScript interpreter from optimizing the program, causing it to run extremely slowly (about 1000 iterations per second on my computer). Using the method above, we run the program in optimized blocks of 20,000 iterations (the first block is actually 19,999 iterations since cr starts from 1, but for simplicity I have said 20,000 throughout the article).
Using an object anonymously in JavaScript
var month = 'Jan'; //or another three-letter abbreviation
//After the following operation, proper_month will contain the string "January".
var proper_month = {'Jan':'January',
'Feb': 'February',
'Mar' : 'March',
'Apr' : 'April',
'May' : 'May',
'Jun' : 'June',
'Jul' : 'July',
'Aug' : 'August',
'Sep' : 'September',
'Oct' : 'October',
'Nov' : 'November',
'Dec' : 'December'
}[month];
How to: Become wise
If you want to become wise, read 100 books that interest you. The books you choose to read can be about any topic and they can be of any quality, good or bad. The important thing is that you should find them interesting, because the fact that you find a book interesting means it contains information that is new1 to you (and thus it increases wisdom), because “interesting” simply means “something that provides new information to the brain”.
No book is going to solve all of your problems. Each book may make you a 1% wiser person. Thus if you want to become double as wise as you are now, you would have to read about 70 books. 100 books would be a safer number.
Some of the books you read will contain false information, because almost any book will contain some claims and assumptions that are false. But if you don’t give up and continue reading books one after another, as your knowledge increases, so will your awareness of what is true and what is false. Wisdom is simply a map of reality (accurate information about how things really are), and each book you read (even a simple story) tries to give you a small piece of the map. Some books will give you false pieces that do not describe anything that actually exists on the map. But as you read more books, your knowledge increases about the other pieces that surround the false piece, and thus you start to have an intuitive sense of what the false piece should actually look like, and thus you recognize the false piece for what it is: false. Recognition of the falsehood in itself increases your knowledge, for your brain can abstract the patterns of falsehood, and it can actually build a map of what falsehood itself looks like, and thus it will become increasingly hard for falsehoods to mislead you.
If you start to read a book that at first seems interesting, but eventually lose interest in it and start to find it boring and tiring, you should feel no qualms about abandoning the book and starting another. When this happens, it can be due to one of two things:
- The book does not contain anything that’s new to you, and thus your brain recognizes it as a repetition of things that you already know very well, and therefore you brain is asking you to stop wasting your time with the book.
- The book contains information that has too many prerequisites, and thus your brain is not equipped to handle the information. You should abandon the book now and return to it after reading many other books.
Spend a year doing this and at the end of it you may laugh at how unwise and biased you used to be a year ago. During your journey you would have picked up some new biases, therefore it is unwise to stop your journey. Continue reading books and these biases will be cleared up. You will never stop picking up biases, but their frequency will decrease as your wisdom increases, for biases have patterns of their own and the wise mind can learn to avoid many of them. This is why you find the wisest people to be those who are least ready to make final judgments on any topic–they are “open-minded”, knowing when they do not have enough information.
In most cases, when it comes to most topics, humans rarely have perfect knowledge, therefore the wisest often refuse to give final answers on anything or to give counsel freely to those who ask for it. They will speak about what they know, and refuse to delve into what they do not know.
Import and play your own audiobooks on the Amazon Fire Phone
[Update: I now recommend using these steps to install the Google Play Store (which does not “root” the device and does not cause any permanent changes), then buying the highly rated Listen Audiobook Player (which has up to 3x playback speed with pitch correction and a slider that shows your place in the book and how much is left–while taking playback speed into account) in the Play Store for $0.99. The entire process takes about 15 minutes.]
Amazon makes it impossible to import audiobooks into the Audible app, probably wanting you to buy all your stuff from them and under their control. I’d actually be more willing to use Audible if it let me import the many audiobooks I already own from other sources. Most Fire Phone audio apps are useless for audiobooks since they do not let you browse the audiobook’s files, instead treating the audiobook as a song album and and making a complete mess out of the order of the tracks. Another issue with music players is playback speed. I usually like to listen to audiobooks at double speed (and usually more if I am able to fully give the book my attention), but most music players I’ve tried on the Fire Phone do not have a playback speed feature.
I was almost losing hope that I would be able to get a proper audiobook experience out of the Fire Phone, until I happened on the Rocket Player App, which has almost all the required features for an audiobook player:
- It allows you to browse the files on the phone and keep the proper order of the tracks (while others players mess up the track order). If the track order is still messed up in Rocket Player, use a free and open-source Windows program called Mp3BookHelper (Project Page | Download Link) to rename the tracks (both file names and the Title ID3 tag) sequentially.
- It has a playback speed setting (after buying the $4 premium version of the app) with pitch correction. The playback speed can only go up to double speed, which is pretty good but I wish it could go up to four.
- It remembers your place in the book, even after closing the app (provided that you do not use the app to listen to other things, which is quite doable since there are many other apps optimized for music listening).
Steps for importing your own audiobooks on the Fire Phone and playing them using Rocket Player
- Install the free Rocket Player App, then upgrade it to the $4 premium version.
- Move your audiobook into a folder on your phone. You can use the USB cable or, if your laptop supports bluetooth, you can use that too, though USB is much faster.
- If you used the USB cable, unplug it, otherwise the audio player may not be able to see the new files.
- Tap the “Folders” tab in Rocket Player. Browse to the audiobook folder (but don’t go inside the folder). Tap the folder and hold, until a menu comes up. Press “Add to playlist” and create a new playlist. Now you can go to the “Playlists” tab to find the audiobook and play it.
- In the Rocket Player settings, you can find the “Playback speed” setting and change it to what you like.
Is reading the Quran better than listening to it?
The majority of scholars (such as Qatar’s Islamic Affairs Ministry, Ibn Baaz, and the UAE Islamic Affairs Ministry) do think that reading is better than listening, but they have no evidence for this except their own personal opinions and unauthentic sayings of the Prophet. To me reading a book or listening to it are the same thing. I listened to the Harry Potter and Lord of the Rings books (instead of reading them with my eyes), does this mean that I somehow understood or “benefited” less from the books than if I had read them?
I suffer from dry eyes and late at night when I read Quran, if my eyes start to feel bad, I switch to listening. Does this mean that God automatically drops my rewards because I decided to receive God’s word through my ears instead of my eyes?
To me, Islam is a religion based on logic, not magic. No good deed is magically better than another, and whether I decide to receive the Quran through my eyes or ears my reward depends on my effort and sacrifice (how much attention I give to the meaning and how much time I dedicate to it), not on some random eyes-are-better-than-ears prejudice.
Growth of CPU GFLOPS by year, with future projections
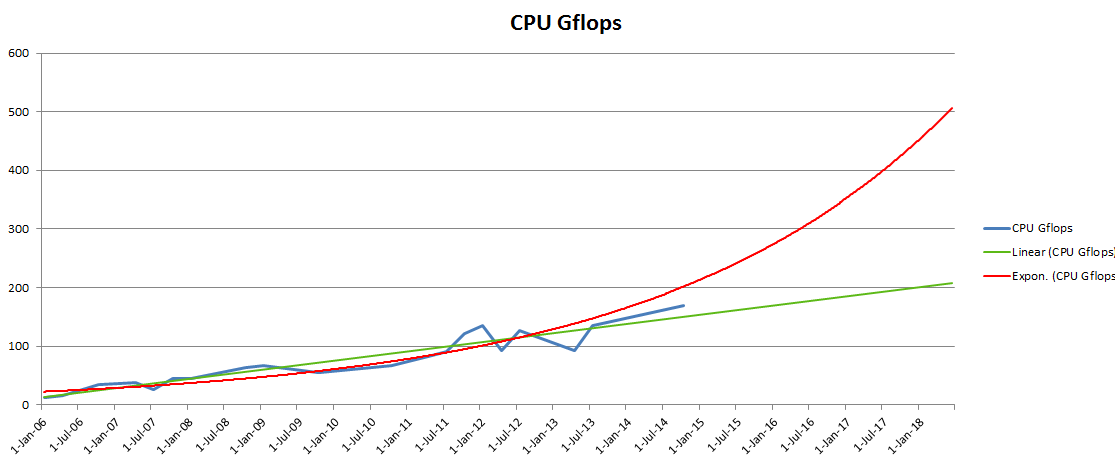
In Q1 2006, the fastest, most expensive CPU could do 12.421 GFLOPS on the Whetstone test. In Q4 2014, the fastest consumer CPU (Intel Core i7-5960X) can do 169.79 GFLOPS.
I added two trend lines to the chart. The green one is a linear trend line, showing that in January 2018 we will have a 200 GFLOPS CPU, which doesn’t sound like much, while the red exponential trend line promises 500 GFLOPS during the same period. The truth will likely be somewhere in between.
The latest CPU’s gains come from its 8 cores, therefore a better performance chart would only show single-thread improvements, since single-thread shows the true performance improvement per core and is a big bottleneck for many games and applications.
A quick single-thread comparison can be done between the Intel Core 2 Extreme X7900 (Q3 2007), which received a single-thread score of 968 on the PassMark test, and the Intel Core i7-2600K (Q1 2011), which received almost exactly double the single-threaded performance at 1943. It took Intel less than 4 years to double the performance of its highest-end consumer CPU. But three years later, the fastest CPU in single-threaded tests is the Intel Core i7-4790K with a score of 2532, meaning that in about four years Intel has only managed to gain a 30% performance improvement in single-threaded applications.
This is a big deal and shows the performance stagnation that gamers and professionals have been complaining about in recent years. If the next four years end up like the past four, in 2018 the fastest consumer CPU will only be 30% faster if no additional cores are added. The interpretation of Moore’s Law that promised a doubling of performance every 18 months has long been inaccurate.
Below is the data that I based the chart on the top on, taken from CPU reviews that featured the SiSoft Sandra Whetstone test.
Quarter GFLOPS 10-Jan-06 12.421 10-Apr-06 15.703 10-Oct-06 33.797 10-Apr-07 37.693 10-Jul-07 26.7 10-Oct-07 44.4 10-Jan-08 44.2 10-Oct-08 62.879 10-Jan-09 66.5 10-Oct-09 55.9 10-Oct-10 67 10-Apr-11 83 10-Jul-11 91 10-Oct-11 121 10-Jan-12 136 10-Apr-12 93.2 10-Jul-12 126 10-Apr-13 93 10-Jul-13 135.4 10-Oct-14 169.79
Using one category page to show multiple categories in WordPress
[Update: There is probably never a good reason to do this. Instead, create a new category to hold the posts.]
Trying to show multiple categories in one loop is easily the hardest thing I’ve done in WordPress.
- First, create a container category where you want your multiple categories to be shown. Let’s call it the MultiCat category and give it the
multicatslug. No posts are required to belong to this category, and if they do, it will have no benefit. - Next, add this bit of code to
functions.phpof your theme. This is where we create a query variable which enables us to identify the multi-category page properly. Update the category slugs below to match the slugs of the categories you want to show together.function multi_cat_handler( $query ) { if ( $query->is_main_query() && $query->query["category_name"] == 'cat1-slug,cat2-slug,cat3-slug,cat4-slug' ) { $query->set("allish",'yes'); } } add_action( 'pre_get_posts', 'multi_cat_handler' ); - Next, add this code to
functions.php. Updatemulticatto the slug of your multiple categories category. Also update the other slugs as in the previous step.function alter_the_query_for_me( $request ) { $dummy_query = new WP_Query(); $dummy_query->parse_query( $request ); if($dummy_query->query['category_name'] == 'multicat') { $request['category_name'] = 'cat1-slug,cat2-slug,cat3-slug,cat4-slug'; } return $request; } add_filter( 'request', 'alter_the_query_for_me' ); - To display the
h1tag of the MultiCat category page properly, we use the following code:if(get_query_var('allish') == 'yes') { echo 'Title of the Multiple Categories Page'; } else { echo 'Normal code that outputs category title'; }If you do not do the above, when people go to the MultiCat category page, they will see a random title from one of the multiple categories you want to show on the page, which is not the behavior you want.
- Below is the main code that outputs your posts. The
ifclause at the top allows us to know we are on the multiple categories page (we cannot use other methods such as checking category ID, since that will return a random category’s ID from the multiple categories we want to show).Here lies the code that outputs your post content Here is the loop that outputs your normal categories
The
$argsarray contains the query we use to pull posts from the database. We are pulling posts from the categories with the IDs of 3, 4, 671 and 672. Notice that in Step 2 we used category slugs, while in this step we are using category IDs. They have to match, and order may matter.
That’s all.
Caveats
The RSS feed of the category page will be the RSS feed of one of the categories shown on the MultiCat page. This may be fixable through using RSS-specific filters, but in my case I had no need for RSS and did not try to find a fix.
How to moderate bbPress submissions that contain links
The most common trait of forum spam submissions is that they contain links. The code below (add it to your main wordpress install’s functions.php theme file) filters new bbPress topics and replies and if it detects a link, it marks the submission as “pending”, allowing moderators to review the submission in the back end before publishing it. The code is working on bbPress version 2.5.4.
The code, however, creates front end issues. If it is a new topic, the user is redirected to a page that contains the topic title but not the topic content. If it is a new reply, the page reloads with no indication of that the reply has been saved. These issues may be solvable with query variables and some jQuery, but in my case, almost all submissions that contain links are guaranteed to be spam, therefore user experience is not a big concern.
function bb_filter_handler($data , $postarr) {
//If the post date and post_modified are the same, it is a new reply/topic. But if they are different,
//it is a moderater editing the reply/topic (such as changing from pending to published status,
//therefore we let the data through without filtering. Without this admins/moderators won't be able to
//change a reply/topic from "pending" status to "published".
if( strtotime($data["post_date"]) != strtotime($data["post_modified"] ) ) {
return $data;
}
if( ($data["post_type"] == 'reply' || $data["post_type"] == 'topic') && $data["post_status"] == 'publish' ) {
$text= $data["post_content"];
$regex = "((https?|ftp)\:\/\/)?"; // SCHEME
$regex .= "([a-z0-9+!*(),;?&=\$_.-]+(\:[a-z0-9+!*(),;?&=\$_.-]+)?@)?"; // User and Pass
$regex .= "([a-z0-9-.]*)\.([a-z]{2,3})"; // Host or IP
$regex .= "(\:[0-9]{2,5})?"; // Port
$regex .= "(\/([a-z0-9+\$_-]\.?)+)*\/?"; // Path
$regex .= "(\?[a-z+&\$_.-][a-z0-9;:@&%=+\/\$_.-]*)?"; // GET Query
$regex .= "(#[a-z_.-][a-z0-9+\$_.-]*)?"; // Anchor
if(preg_match("/$regex/", $text)) {
$data["post_status"] = 'pending';
} else {
//do nothing
}
}
return $data;
}
add_filter( 'wp_insert_post_data', 'bb_filter_handler', '99', 2 );
Using jQuery and JSON to recover from a failed TablePress save
I was happily working away on my 700+ row table in TablePress, saving occasionally. Server issues came up and I was prevented from saving for a few hours. Eventually the server was back up again and I wanted to save, but I ran into the dreaded Ajax save failure message.

Even using shift+save did not work, taking me to the silly and useless Are you sure? WordPress page.
Refreshing the page would have meant losing many hours of work. I tried various ideas but all failed. The most desperate idea was to use jQuery to get the values of all the table cells, put them into an array, copy the string of the array, refresh the page, use jQuery to feed the array back into the cells. I tried to do it in Firefox, using the built-in inspector and Firebug, only to be reminded of how much I dislike Firefox’s slow and clunky inspector tools (I was using Firefox since it performs better than Chrome on super-sized web apps like a massive TablePress table).
So I needed a way to move my work to Chrome, but how? I saved the TablePress page as an HTML document on my computer, then opened it in Chrome. Saving the editor as an HTML document causes the values of the input fields to be saved, thus when I opened it in Chrome all the values of the cells where there.
Next, I used a jQuery bookmark to load jQuery on the page in Chrome, then I ran the following two lines in the console:
my_array = [];
$('textarea').each(function(){ my_array.push($(this).val()); });
The above code loads the values of the textboxes into an array. The Chrome console doesn’t have a way of letting you copy an object or array’s source code so that you can paste it somewhere else, therefore we have to improvise. We know that the console will print out the value of any object, and if it is a string, it will plainly print the string.
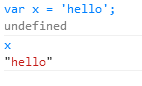
In the above example, we place the word “hello” in the variable x, then on the next line simply write the name of the variable and press enter, causing chrome to give us the string “hello”. As seen below, if type the name of an array variable, Chrome enables us to browse the values inside the array. This is usually helpful, but not this time, since we need the array in format that can be copied.
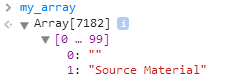
What we need is to stringify the array somehow. In this case, the JavaScript JSON API comes to the rescue. We place the array my_array inside the my_string variable using the line below:
var my_string = JSON.stringify(my_array);
Afterwards, we type my_string into the console, causing Chrome to show the plaintext version of the array:

We then copy the entire text (making sure to skip the beginning and end quotes added by the stringify function, since we won’t be needing them), then open the TablePress backend on a new tab, loading the table we were working on. The table will lack the cells we had added but could not save. Now we populate this working backend with the data we copied. We open the console, re-enable jQuery using the bookmark, and use the following line to load the text into an array. We do not have a need to use the JSON API’s parse function, since the plaintext is already a valid array initialization.
Below we see the array my_array, ready to be populated with the string we copied:

Next, we use the line below to add the values of the array into the table:
$('textarea').each(function(){ $(this).val(my_array.shift()); });
All done! In the first .each function above, we used my_array.push() to add values to the end of the array. To keep the values in order, we now use my_array_.shift(), getting items from the beginning of the array and feeding them to the textareas from first to last.
In this way I managed to get my work back. Another solution I could have tried would have been to see if WordPress could be forced to accept the data that it was rejecting (it was rejecting it due to an expired session or something like that). But such a solution may have required a lot more work and possibly modifications to the WordPress core, which is always risky and not fun.
How to automate and throttle Relevanssi indexing on large websites
First of all, update Relevanssi to the latest version. This significantly increased indexing performance on my 80,000+ page website.
Next, I created the following hacky solution for a problem that shouldn’t exist; the fact that Relevanssi cannot silently index everything without hogging all server resources. First find out the number of pages Relevanssi can index in one go without overloading your server, say 500. Then use the following Tampermonkey script on the Relevanssi settings page. You need Chrome’s Tampermonkey extension. Here’s what the script does:
- It enables jQuery on the Relevanssi dashboard.
- It waits 15 seconds, then clicks the “Continue indexing” button. Once the indexing is done and the page reloads, it waits 15 seconds, then clicks it again, and so on.
- Leave this running in a tab until all pages are indexed, then turn the script off and close the tab.
Below is the code:
// ==UserScript==
// @name Relevanssi Index Button Clicker
// @namespace http://hawramani.com
// @version 0.1
// @description Click click click
// @match http://mywordpressite.com/wp-admin/options-general.php?page=relevanssi/relevanssi.php
// @copyright 2014 jQuery, Ikram Hawramani
// ==/UserScript==
(function () {
function loadScript(url, callback) {
var script = document.createElement("script")
script.type = "text/javascript";
if (script.readyState) { //IE
script.onreadystatechange = function () {
if (script.readyState == "loaded" || script.readyState == "complete") {
script.onreadystatechange = null;
callback();
}
};
} else { //Others
script.onload = function () {
callback();
};
}
script.src = url;
document.getElementsByTagName("head")[0].appendChild(script);
}
loadScript("https://ajax.googleapis.com/ajax/libs/jquery/1.6.1/jquery.min.js", function () {
//jQuery loaded
console.log('jquery loaded');
setTimeout(function(){$('[name="index_extend"]').click();},15000);
});
})();
How cyber pirates anonymously torrent movies on the internet
For my views on Internet piracy see my essay: Why Digital Piracy is Ethical and Necessary
We all know that you, as a law-abiding citizen, would never download a car. And yet there are people out there who download movies for free and refuse to add a few more bucks to the billions of dollars that movie studios squat upon. There are film executives who, thanks to cyber pirates, only have a net worth of $100 million instead of $101.
So how do they do it? How are these cyber criminals subverting our democracy and freedoms to acquire knowledge and entertainment for free without making the wealthy even wealthier? It all burns down to three simple letters: I2P.
I2P, or the Invisible Internet Project, is a project that enables anyone anywhere to download information in a way that makes it impossible for anyone to track them or reveal their identity. Many experts at the CNN agree that our democracy is in great danger when we freely allow citizens to practice speech that is genuinely free. Speech needs to be controlled and approved by the government, for our own security, and most importantly, the safety of our children. The cyber police work tirelessly to prevent free speech from actually taking place. But the pirates have found a home in I2P where no one can catch them.
I2P is slightly like TOR, which you may have heard of. However, unlike TOR, I2P is not used to browse normal internet sites (though it can be used that way), rather, it has its own sites, such as stats.i2p. And unlike TOR, I2P supports and encourages torrenting; it even has a built-in torrent client that is ready to go as soon as you install I2P.
Cyber pirates follow the following steps when they download high quality Blue Ray movies, ebook and textbook collections, and the latest Battlefield video game anonymously. We can show you the steps since downloading, installing and using I2P is perfectly legal under current laws (so long as you do not intentionally seek out and download copyrighted movies, books, songs, etc., see step 18 below for more clarification on this).
- First, they visit the I2P site to download the I2P software:
If the site is for some reason down or has moved, they can easily find the new site by Googling “download i2p”:
- Then they click the I2P download link to download the I2P software:

- Below is a picture of the finished I2P software download:

- They may then do a signature check to make sure their version of I2P has not been tampered with. You can read TOR’s guide for how to do this, and apply the same logic to I2P.
- Once I2P is installed, they do not run it. They will set up a browser to be fully dedicated to I2P. This means that the browser will be able to browse I2P websites, but not ordinary internet sites. In our example we show how the Opera browser can be configured to handle I2P. They click on the Opera button, then point to Settings->Preferences:
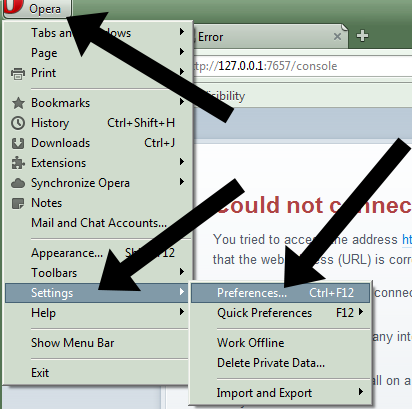
- Then they click the Advanced tab:
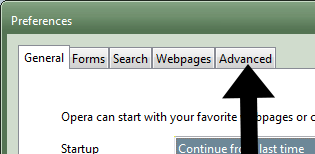
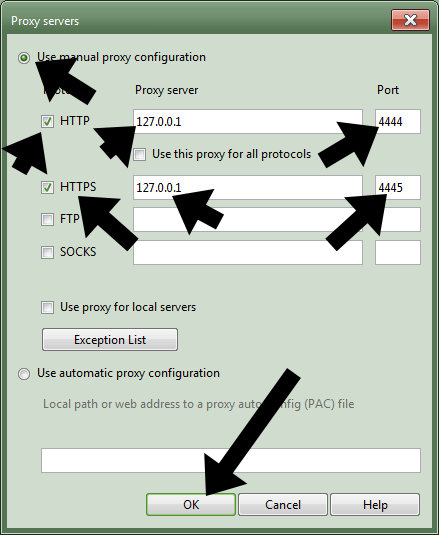
- Then they click on the Network section, then the “Proxy servers” button:

- Then they make the following changes to the window that pops up, then click “OK”:
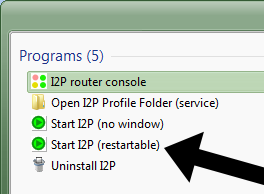
- Once they are done setting up Opera, they start I2P. There are two programs, and it doesn’t matter which one you run, the only difference is that the second one has a restart option. In our example we show you the restartable one:
- The I2P Service window shows up for them. Here they wait a little while for the program to fully start up.
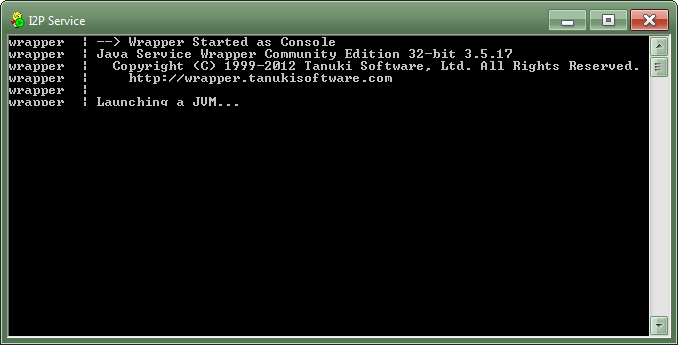
- If all goes well, their computer launches their default browser, which could be Internet Explorer. While they do not want this, it is useful for getting the address to the I2P service. Thus they copy the address shown.
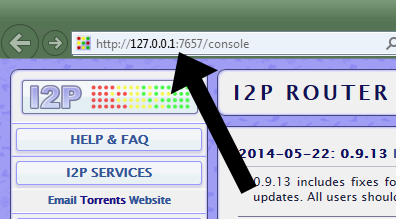
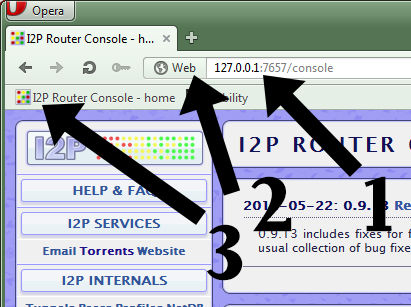
- They go to Opera and paste the address in the address bar. Then they drag the icon where it says “Web” to the bookmarks bar for easy navigation in the future.
- They wait a while as their I2P program becomes integrated into the worldwide network. They watch these two indicaters on the I2P homepage. Once they are green, they know they are good to go:
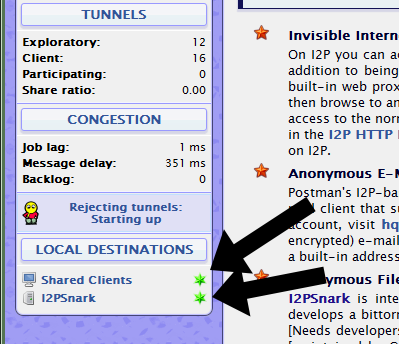
- Now, they click on the “Torrents” link at the top of the I2P Console.
- They are taken to I2PSnark, which is the built-in torrent client for I2P. Currently the client is empty since we haven’t added any torrents. They click on the “Postman” link to take them to the Postman tracker, which is the largest torrent tracker on I2P. There is also the Diftracker link, which is another tracker.
- Depending on how long the I2P program has been running, the Postman website will open immediately or after a while. They may also get a “Proxy server error” kind of page, which is nothing to be worried about, they will simply try the website again in 5-10 minutes.
In the image it can be seen that the sneaky anonymous cyber pirates have uploaded torrents for a movie called Let the Right One In and a video game called Wasteland 2.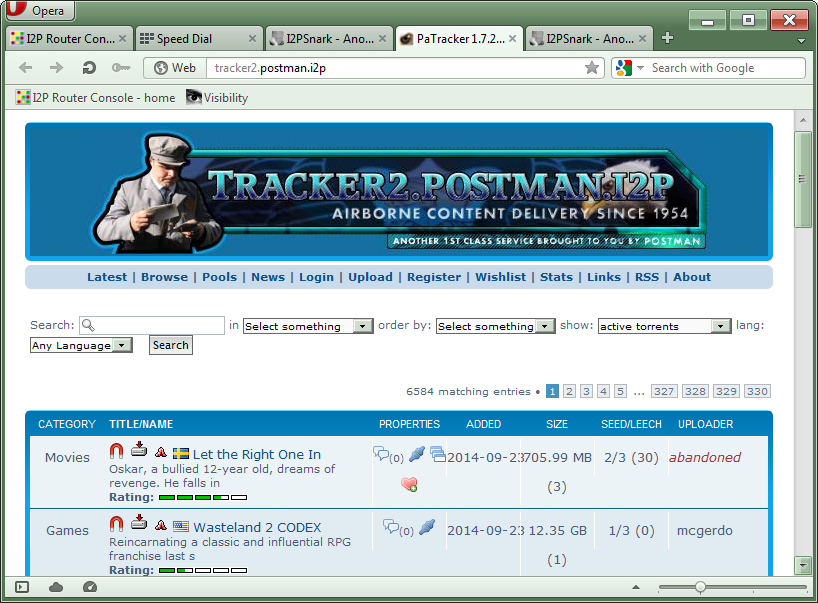
- Since we are perfectly law-abiding citizens, we will show an example of downloading a legal non-copyrighted file from the Postman I2P bittorrent tracker. But the pirates download movies and other files, committing copyrighted infringement. Of course, nobody, government or otherwise, can catch them do it, since everything is fully anonymous and encrypted. So they get away with downloading their favorite movies without making the super wealthy even wealthier. The communism!
Here, to find a legal file, we put the keyword “pdf” into the search box so that we only see ebook files, some of which are copyright-free and legally distributable.
- Here is an example of some of the books that came up. We find some German magazine, a book by John Gray for clueless men trying to lead a politically correct life, two sex guides for autistic individuals, some convoluted self help nonsense, and a book for antenna nerds. These are all copyrighted books, therefore we will have to skip them; we wouldn’t download a car, so why would we download books? Of course, balaclava-wearing cyber pirates do not skip them just because they are copyrighted, since they know the cyber police have no way of catching them, since they are using I2P.
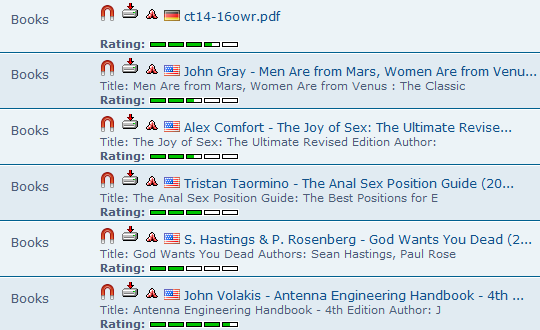
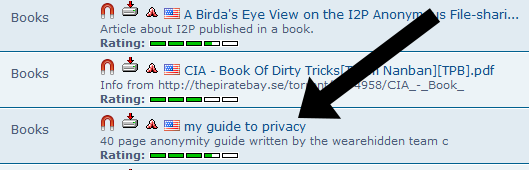
- After a very, very long time, we find a book that seems copyright-free.
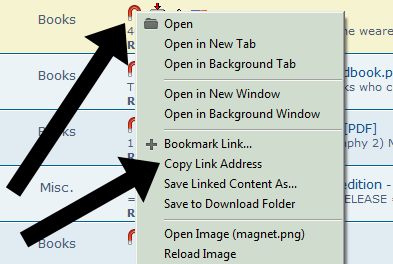
- Here, the pirates will right-click the magnet icon on the left of the book title and click “Copy Link Address”.
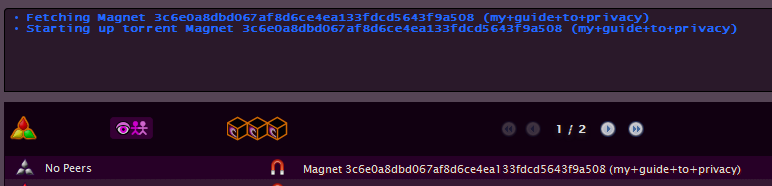
- Then, they will go back to I2PSnark, paste the link in the “From URL” box, then click “Add torrent”.

- Below we see that the torrent has been added to the list of torrents. The word “Magnet” ahead of all those numbers tells the pirate that the torrent file hasn’t been fetched yet (it usually takes a minute or two). Once it is, the name for the torrent will be shown.
- Below you can see the finished torrent being seeded. We have blacked out the names of the other torrents for undisclosed reasons. Seeding is also perfectly anonymous; therefore pirates often leave many torrents running in the seeding mode to help other pirates download things faster. Due to all of the cryptography that happens, downloading more than 5 torrents at the same time can cause significant CPU usage.
No Reddit table maker? How to easily put a large table on reddit
It is pretty easy to put a table on reddit. Below are step-by-step instructions:
- If the data is on a website, or in an Excel spreadsheet (you can skip these if not):
- Create a new spreadsheet and paste your data in there.
- Save your data as a comma-separated text file (CSV).
- Open the file in notepad (or another plain text editor) and copy.
- Go to Truben.no.
- If you copied your data from a CSV (as in step 1), go to file->import and choose CSV, then paste what you copied in step 1.3.
- If you are making a table from scratch, simply enter your data into the boxes you see. Use the menus to modify the table to fit your needs.
- Once you have your data, click on the Markdown tab.
- Copy the text you see below the tab and paste it in the reddit editor.
Using query_posts() as if it is get_posts()
Some filters work only with query_posts(); but what if you wanted to use one of these filters in a situation where you would normally use get_posts()? Below is the translation:
Original get_posts() query:
$args = array('orderby'=> 'title', 'order' => 'ASC','fields' =>'ids');
$posts_array = get_posts($args);
Translated to query_posts():
$args = array('posts_per_page'=>-1, 'orderby'=> 'title', 'order' => 'ASC','fields' =>'ids');
// the -1 means return all posts, without it you will get the
// number of posts you've set your blog to show per page
$posts_array = query_posts($args);
// do your thing here
wp_reset_query(); // this stops your get_posts() query from affecting other functions;
// without it functions like is_single() will break
How to ignore accents and other diacritics in WordPress/MySQL search (Arabic, French, etc.)
On my new Asmaa.org website, which is an Arabic-language baby name resource, I use a simple loop to show the posts in alphabetical order. Each post title is a baby name:
$args = array( 'paged' => $paged, 'orderby'=> 'title', 'order' => 'ASC', 'cat' => $cat_id); query_posts($args); ?> while ( have_posts() ) : the_post()
Since the Arabic alphabet is an abjad, most vowels are added to a word as diacritical marks. This has the unfortunate consequence of causing علم and عَلَم, two words that should be shown very close next to each other, to be shown miles apart in an alphabetical sort.
I solved the issue with this WordPress filter:
add_filter('posts_orderby', 'cleanse_diacritics');
function cleanse_diacritics($d) { //$d is this string: 'wp_posts.post_title ASC' (or sth similar) in a default WordPress install
//assuming you are sorting alphabetically ascending
if(strpos($d,'title') !== false) { //if the string 'title' is in the orderby query, we know that
//we are dealing with an alphabetical sort.
//no need to mess with other queries like order by post_date
// below we replace the default order query WordPress passes to MySQL by
// using a whole bunch of replaces to remove diacritics from the sorting
$d = 'REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(HEX(REPLACE(
wp_posts.post_title, "-", "")), "D98E", ""), "D98B", ""), "D98F", ""), "D98C",
""),"D991",""),"D992",""),"D990",""),"D98D","") ASC';
}
return $d;
}
I got the nested MySQL replace() functions from this StackOverflow answer.
Explanation: When you run a query_posts(array('orderby' => 'title') function or something similar, the posts_orderby filter can be used to modify the order by part of the MySQL query. We wrap the name of the relevant MySQL column in replace() functions to remove all diacritics using their hex UTF-8 code units, which results in a diacritic-insensitive sort.
If you are dealing with a language other than Arabic, you may need to replace a code with another code (é [C3A9] to e [65] for example) instead of replacing with an empty string.
Considerations
The filter posts_orderby does not seem to work with get_posts(). There is a workaround however; see: Using query_posts() as if it is get_posts().